After getting chores done for the day I set about working on my new blog engine. This started out with getting flask templates working and after some back and forth that was sorted out. It then set in that I was repeating myself a lot because I skipped an ORM model. So I set about to write a blog class to handle loading, serialization, updates, and inserts. A round of testing later and a bunch of bugs were squashed.
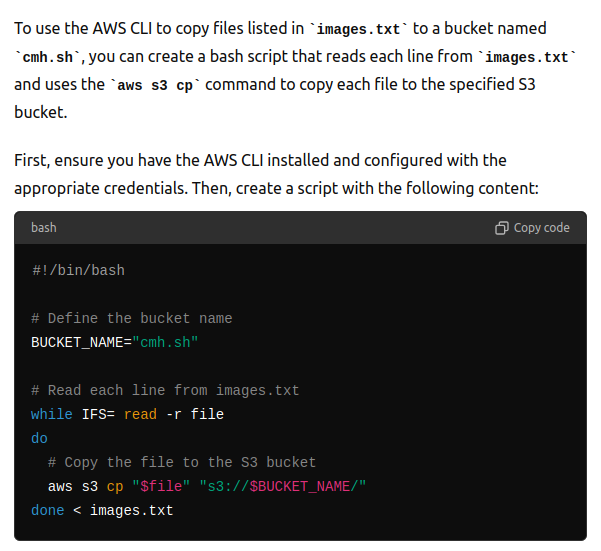
A side quest today was to update all of the image paths from prior blog posts to use my CDN. I ended up using a combination of awk commands [ awk '{print $7}' images.txt > just_images.txt and awk -F '/' '{print $3}' image_names.txt > images2.txt] to get a good list of images to push to the CDN and then asked chatgpt to help me write a bash loop [ while IFS= read -r file; do aws s3 cp "$file" s3://cmh.sh; done < images2.txt ] to copy all the images.
 I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.
I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.
Since the weather was suppose to be hotter today and it was suppose to storm throughout the day, I opted to work on my tech projects today. I started the day by streaming my work on Raphael bot, where I quickly was able to fix the issue where Raphael was ignoring me. Next I turned my attention to the scene switching command. After adding several variants to the list of commands I was able to get a demo working quite well on stream and pushed the changes to my GitHub Repository.
With Raphael being in a good place, I turned my attention to my new flask based blog engine. After some troubleshooting I was able to find a problem, and figured out that part of the issue with my curl test commands was that I wasn’t saving the cookie that curl was getting from the login api call. With my curl issues solved, I turned to obscuring my blog user password when calling my curl commands. The last thing I worked on before turning my attention to a discord movie watch party was adding a file upload method to my blog API. With the hours of my Sunday winding down, I turned my attention to the documentation for Raphael since I noticed that someone had started following the repository.
Demo:
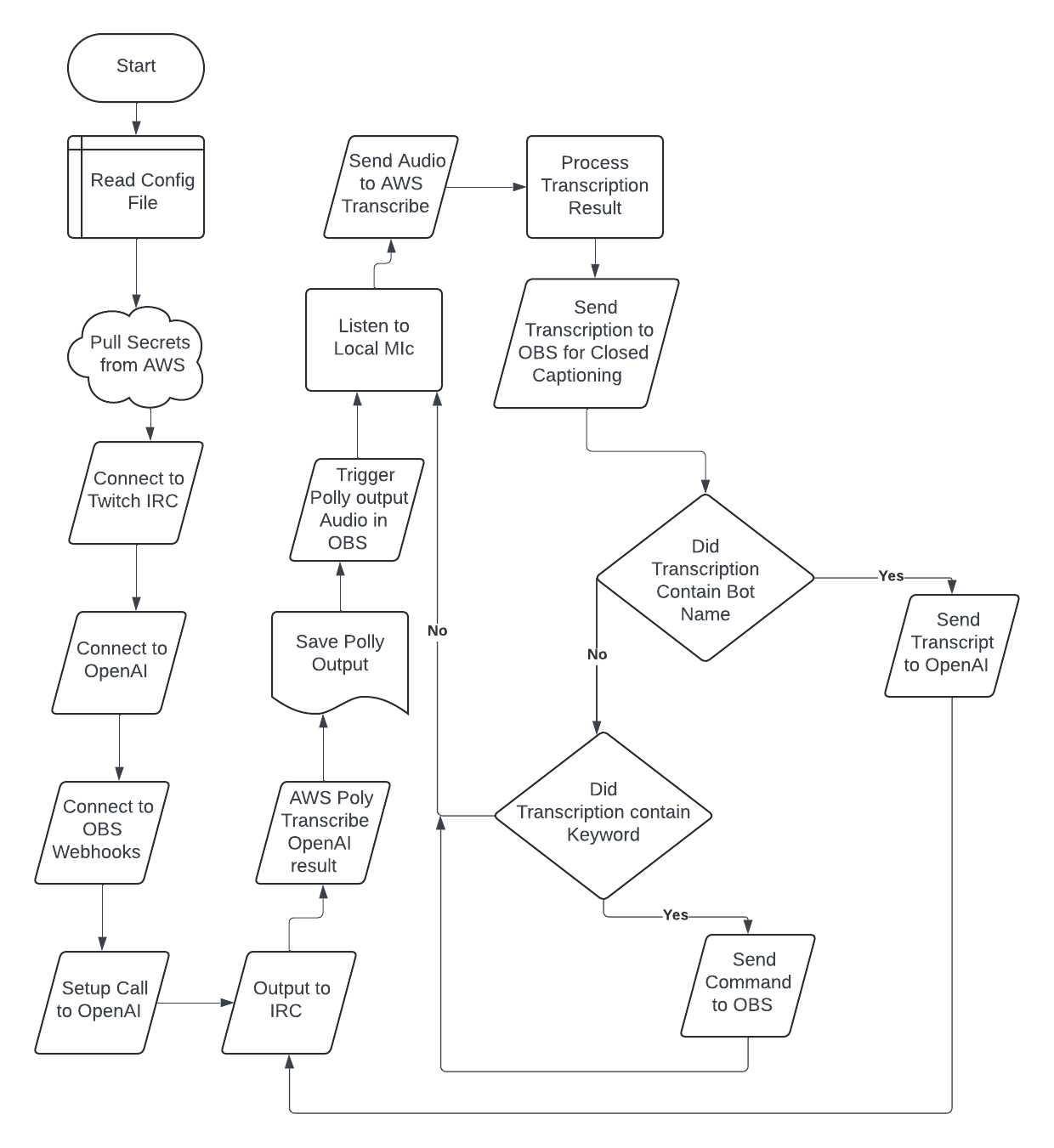
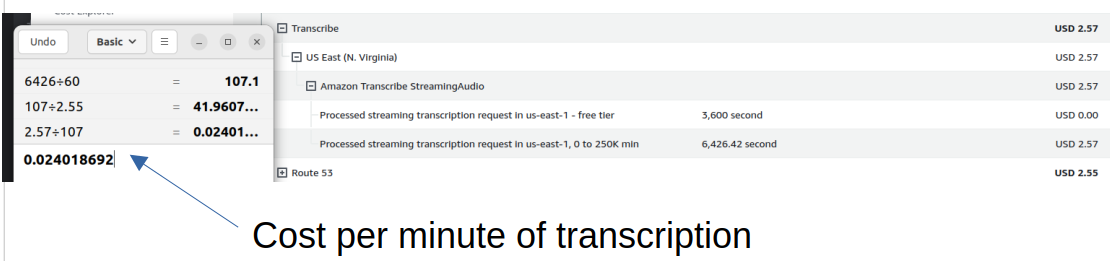
Today’s focus was on getting closed captioning working for Raphael bot. The solution ended up being switching the type of text I was creating and not worrying about the layout and location of the text. Left to the user to adjust the text location, adding the code to send all the transcriptions to the stream was not a big deal. The rest of my time was spent cleaning up the code and documentation. I also dropped a comment on my tiktok showing off the bot on tik-tok that the source code was available on GitHub. The other thing that I learned today was that Raphael is too expensive for most full time twitch streamers. I also dropped a comment on my TikTok showing off the bot on TikTok that the source code was available on GitHub.. The AWS transcription service costs about $0.024 cents per minute. This means that a typical full-time Twitch streamer would spend over $40 a week just on the transcription service. I suppose it’s a good thing that the code is open-source.
This week has seen a lot of my spare time trying to finish solving a problem I encountered at last weekend's tail end. Why my EC2 vm with an IAM profile that should grant it access to an s3 bucket can’t use the AWS PHP SDK to connect to the S3 bucket. I kept getting variations of this exception:
| [Fri Jun 28 22:47:50.774779 2024] [php:error] [pid 38165] [client 1.2.3.4 :34135] PHP Fatal error: Uncaught Error: Unknown named parameter $instance in /home/notarealuser/vendor/aws/aws-sdk-php/src/Credentials/CredentialProvider.php:74\nStack trace:\n#0 /home/notarealuser/vendor/aws/aws-sdk-php/src/Credentials/CredentialProvider.php(74): call_user_func_array()\n#1 /home/notarealuser/vendor/aws/aws-sdk-php/src/ClientResolver.php(263): Aws\\Credentials\\CredentialProvider::defaultProvider()\n#2 /home/notarealuser/vendor/aws/aws-sdk-php/src/AwsClient.php(158): Aws\\ClientResolver->resolve()\n#3 /home/notarealuser/vendor/aws/aws-sdk-php/src/Sdk.php(270): Aws\\AwsClient->__construct()\n#4 /home/notarealuser/vendor/aws/aws-sdk-php/src/Sdk.php(245): Aws\\Sdk->createClient()\n#5 /var/www/blog/s3upload.php(35): Aws\\Sdk->__call()\n#6 {main}\n thrown in /home/notarealuser/vendor/aws/aws-sdk-php/src/Credentials/CredentialProvider.php on line 74 |
I didn’t want to but I ended up adding the aws cli to my test box and confirmed that I could indeed access my aws bucket without using any hard coded credentials on the box using the IAM profile for the ec2 running this code. I ended up calling the AWS CLI from my code directly. This isn’t ideal, but I’ve wasted enough time this week fighting with this bug. In other news ChatGPT is pretty fantastic at writing regular expressions and translating english into sed commands for processing text data. Because I had to use the AWS CLI, I was getting the contents of my S3 Bucket back as text that wasn’t in a format that was ideal for consuming by code. Here is the prompt I used and the response.

I validated that the sed was correct on the website https://sed.js.org/

ChatGPT also provided a useful breakdown of the sed command that it wrote. 
One more tool for my toolbox for working with files in nix environments.
Before I finished my Juneteenth holiday break I posted the source code for Raphael bot out on github. I got the voice recognition working and responding in a timely manner. It even outputs it’s voice to obs studio. For some reason I was feeling brave and posted a tik-tok with the video . The next step will be to implement the streaming commands in a manner that allows customization. I also added a readme.md which still has a lot to be desired as I haven’t done any testing outside of Ubuntu 22.04. This weekend I randomly decided to make myself a url shortner for a new domain I acquired. Finished that up today.
I've been working on a Twitch bot for a couple weeks now. I've got transcription mostly working. So far, I have gotten chat messages going to Twitch chat, and the bot recognizes it's name. When it recognizes its name and calls ChatGPT to answer questions for the streamer.