from getpass import getpass
import requests
import json
import os
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
username = "colin@cmh.sh"
password = getpass()
session = requests.Session()
session.headers.update({
'Accept': "application/json",
'Content-Type': "application/json",
'Cache-Control': "no-cache",
})
url_authn = f"{os.environ.get("OKTA_ORG_URL")}/api/v1/authn"
logger.info(f"auth URL: {url_authn}")
payload_authn = json.dumps({
"username": username,
"password": password,
"options": {"warnBeforePasswordExpired": True,
"multiOptionalFactorEnroll": True},
})
response = session.post(url_authn, data=payload_authn)
logger.info(f"auth response: {response.text}")
resp_obj = json.loads(response.text)
if resp_obj["status"] != "SUCCESS" and resp_obj["status"] != "MFA_REQUIRED":
logger.error(f"auth response: {resp_obj["status"]}")
raise "Login failed"
if resp_obj["status"] == "MFA_REQUIRED":
factors = resp_obj["_embedded"]["factors"]
logger.info(f"factors: {factors}")
factorId = getpass(prompt="factor id: ")
mfa_otp_url = f"{os.environ.get("OKTA_ORG_URL")}/api/v1/authn/factors/{factorId}/verify"
#https://developer.okta.com/docs/reference/api/authn/#verify-totp-factor
otp = getpass(prompt="OTP:")
mfa_payload = json.dumps({
"stateToken": resp_obj["stateToken"],
"passCode": otp
})
logger.info(f"MFA URL: {mfa_otp_url}")
mfa_resp = session.post(url=mfa_otp_url, data=mfa_payload)
logger.info(f"mfa response: {mfa_resp.text}")
resp_obj = json.loads(mfa_resp.text)
if resp_obj["status"] != "SUCCESS":
logger.error(f"mfa response: {resp_obj["status"]}")
raise "MFA failed"
logger.info(f"Successfully logged into okta. sessionToken: {resp_obj['sessionToken']} userID: {resp_obj['_embedded']['user']['id']}")
source /media/vacuum-data/update_internal_dns_auto.sh
#Kubernetes related
sudo curl -sSL https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
mkdir /tmp/working
chmod 777 /tmp/working
K3S_URL=$(cat /media/vacuum-data/k3s/k3s_url)
K3S_TOKEN=$(cat /media/vacuum-data/k3s/k3s_token)
# Get the secret value and store it in a variable
secret_string=$(aws secretsmanager get-secret-value \
--secret-id "$SECRET_ARN" \
--query 'SecretString' \
--output text)
# Parse the JSON and extract the values using jq
# Note: You'll need to install jq if not already installed: sudo yum install -y jq
K3S_POSTGRES_USER=$(echo $secret_string | jq -r '.K3S_POSTGRES_USER')
K3S_POSTGRES_PASSWORD=$(echo $secret_string | jq -r '.K3S_POSTGRES_PASSWORD')
POSTGRESS_SERVER=$(echo $secret_string | jq -r '.POSTGRES_SERVER')
con="postgres://$K3S_POSTGRES_USER:$K3S_POSTGRES_PASSWORD@$POSTGRESS_SERVER:5432/kubernetes"
postgres_conn_k3s=${con}
echo "postgres_conn_k3s is set to $postgres_conn_k3s"
# Download the RDS CA bundle
curl -O https://truststore.pki.rds.amazonaws.com/global/global-bundle.pem
# For k3s configuration, you'll want to move it to a permanent location
sudo mkdir -p /etc/kubernetes/pki/
sudo mv global-bundle.pem /etc/kubernetes/pki/rds-ca.pem
#ECS related
if [ -d /etc/ecs ]; then
echo "ECS_CLUSTER=vacuumflask_workers" > /etc/ecs/ecs.config
echo "ECS_BACKEND_HOST=" >> /etc/ecs/ecs.config
#TODO: set hostname; set name in /etc/hosts
#TODO: register with ALB.
fi
MAX_ATTEMPTS=60 # 5 minutes maximum wait time
ATTEMPT=0
API_URL="https://vacuumhost1.internal.cmh.sh:6443"
# Check if a k3s node is already online
response=$(curl -s -o /dev/null -w "%{http_code}" \
--connect-timeout 5 \
--max-time 10 \
--insecure \
"$API_URL")
if [ $? -eq 0 ] && [ "$response" -eq 401 ]; then
curl -sfL https://get.k3s.io | sh -s - server \
--token=${K3S_TOKEN} \
--datastore-endpoint=${postgres_conn_k3s} \
--log /var/log/k3s.log \
--tls-san=${API_URL}
else
# Install k3s with PostgreSQL as the datastore
#this is only if there isn't an existing k3s node
curl -sfL https://get.k3s.io | sh -s - server \
--write-kubeconfig-mode=644 \
--datastore-endpoint=${postgres_conn_k3s} \
--log /var/log/k3s.log \
--datastore-cafile=/etc/kubernetes/pki/rds-ca.pem \
--token=${K3S_TOKEN} \
# --tls-san=${K3S_URL} \
fi
echo "Waiting for k3s API server to start at $API_URL..."
while [ $ATTEMPT -lt $MAX_ATTEMPTS ]; do
# Perform curl with timeout and silent mode
response=$(curl -s -o /dev/null -w "%{http_code}" \
--connect-timeout 5 \
--max-time 10 \
--insecure \
"$API_URL")
if [ $? -eq 0 ] && [ "$response" -eq 401 ]; then
echo "K3s API server is ready!"
break;
else
ATTEMPT=$((ATTEMPT + 1))
remaining=$((MAX_ATTEMPTS - ATTEMPT))
echo "Waiting... (got response code: $response, attempts remaining: $remaining)"
sleep 5
fi
done
if [ $ATTEMPT -eq $MAX_ATTEMPTS ]; then
echo "K3s API server did not start in time. Exiting."
exit 1
fi
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
pwd=$(aws ecr get-login-password)
echo $pwd | sudo docker login --username AWS --password-stdin 123456789.dkr.ecr.us-east-1.amazonaws.com
kubectl delete secret regcred --namespace=default
# Create a secret named 'regcred' in your cluster
kubectl create secret docker-registry regcred \
--docker-server=123456789.dkr.ecr.us-east-1.amazonaws.com \
--docker-username=AWS \
--docker-password=${pwd} \
--namespace=default
kubectl create secret tls firstlast-tls \
--cert=/media/vacuum-data/vacuum-lb/ssl/wild.firstlast.dev.25.pem \
--key=/media/vacuum-data/vacuum-lb/ssl/wild.firstlast.dev.25.key \
--namespace=default
kubectl create secret tls cmh-tls \
--cert=/media/vacuum-data/vacuum-lb/ssl/wild.cmh.sh.crt \
--key=/media/vacuum-data/vacuum-lb/ssl/wild.cmh.sh.key \
--namespace=default
helm repo add traefik https://traefik.github.io/charts
helm repo update
helm install traefik traefik/traefik --namespace traefik --create-namespace
kubectl apply -f https://raw.githubusercontent.com/traefik/traefik/v2.10/docs/content/reference/dynamic-configuration/kubernetes-crd-definition-v1.yml
cd /media/vacuum-data/k3s
source /media/vacuum-data/k3s/setup-all.sh prod
my diy helm
#!/bin/bash
if [ -z "$1" ]
then
echo "No config supplied"
exit 1
fi
if [ ! -f "$1" ]
then
echo "File $1 does not exist"
exit 1
fi
export $(cat .env | xargs)
envsubst < $1 > $1.tmp
kubectl apply -f $1.tmp
rm $1.tmp
kubectl get pods
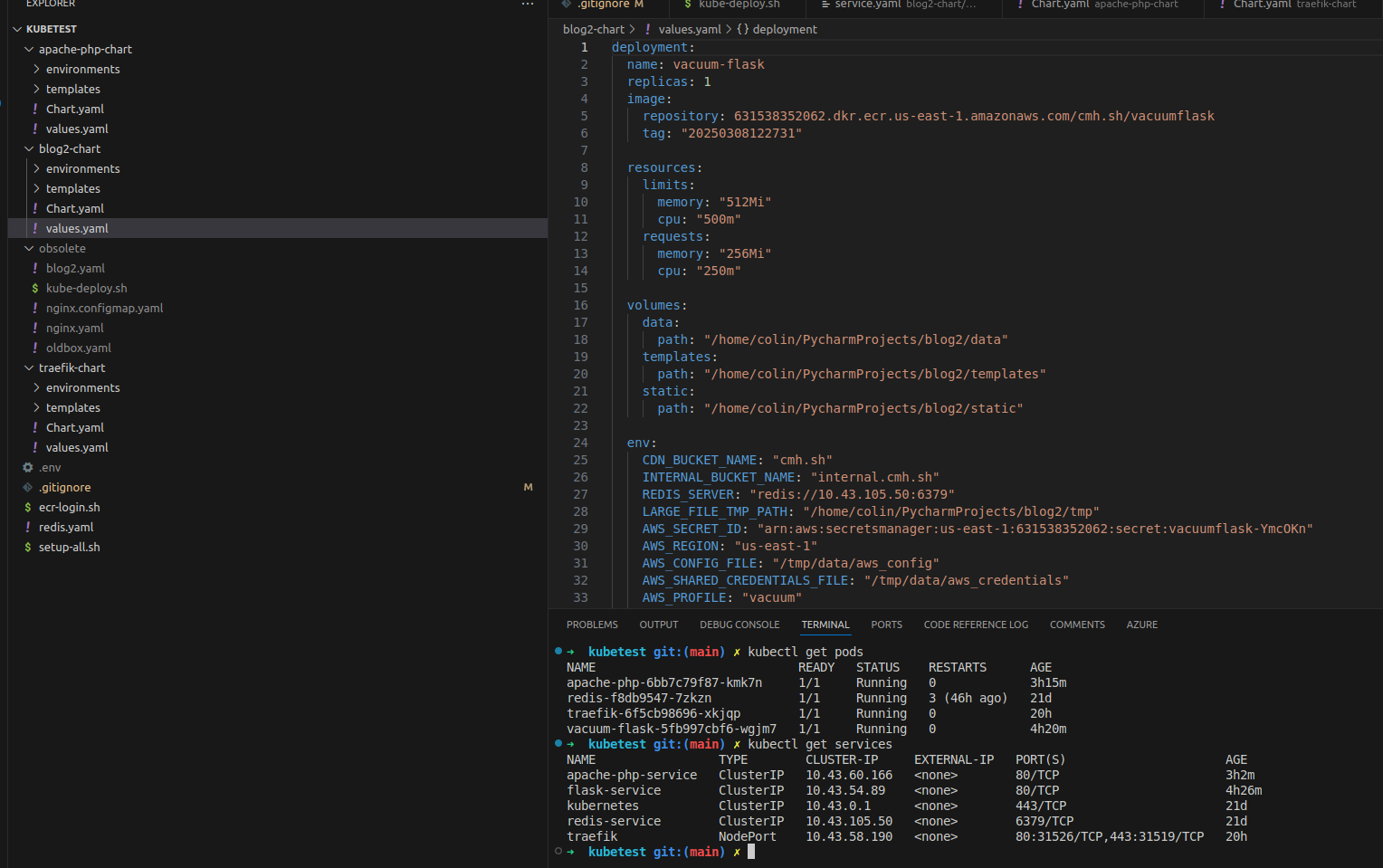
Handy kubectl commands
- kubectl get pods
- kubectl logs podid
- kubectl describe pod podid
- kubectl get services
- helm template apache-php ./apache-php-chart -f environments/values-dev.yaml
- helm uninstall apache-php
- kubectl get endpoints flask-service
- kubectl get ingressroutes -A
- helm install blog2-dev ./blog2-chart -f blog2-chart/environments/values-dev.yaml
#!/bin/bash
# Load all the environment variables from the .env file
export $(cat .env | xargs)
#Take the task definition file and replace the environment variables
envsubst < tomcat-task-def-template.json > task-definition.json.tmp
if [ ! -f task-definition.json.tmp ]; then
echo "task-definition.json.tmp is missing"
exit 1
fi
full_path=$(pwd)
# Register the task definition
aws ecs register-task-definition --cli-input-json file:///${full_path}/task-definition.json.tmp
read -p "Remove the temp file? [y/n] " -n 1 -r removetempfile
if [[ $removetempfile =~ ^[Yy]$ ]]
then
rm task-definition.json.tmp
fi
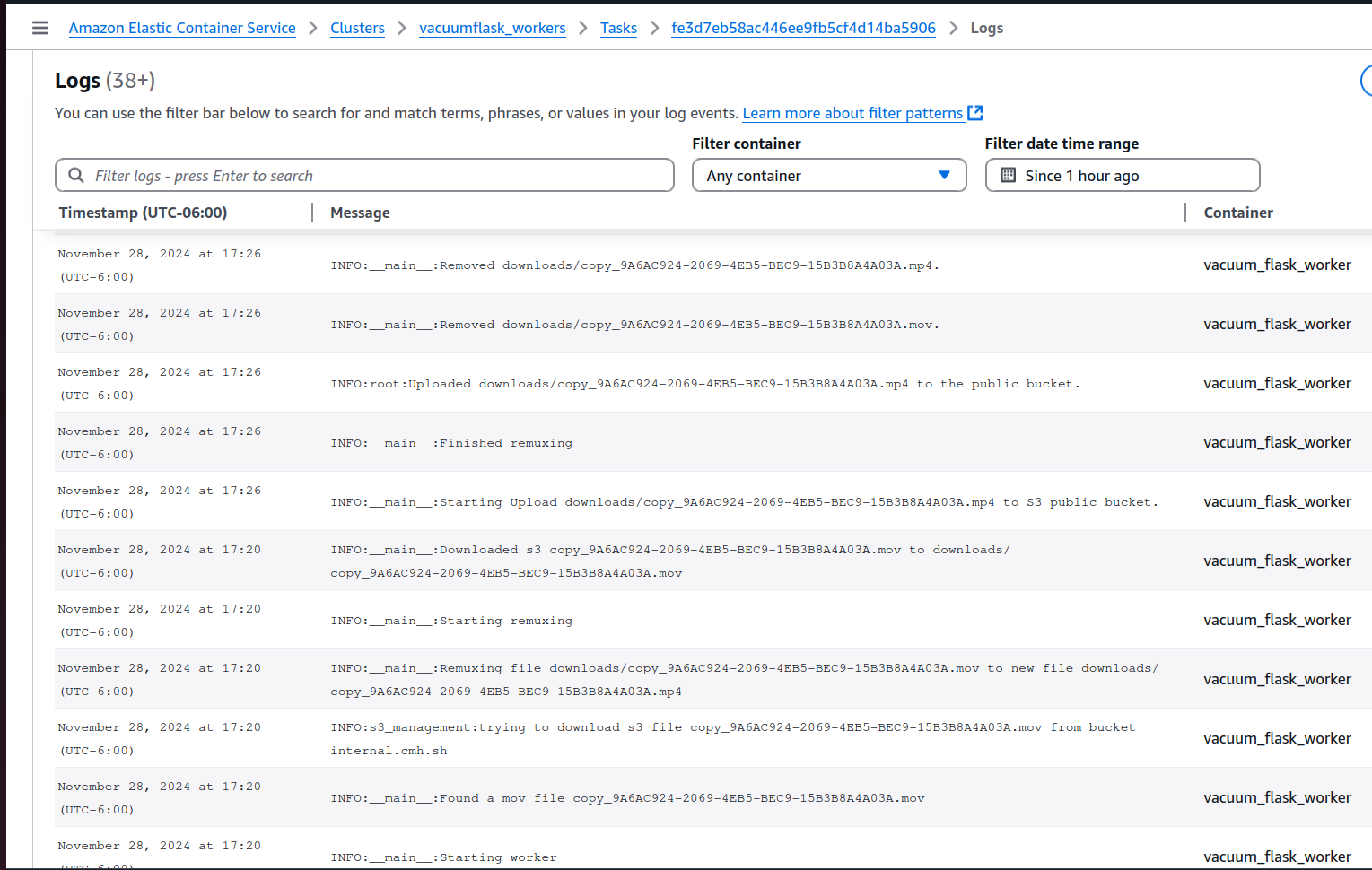
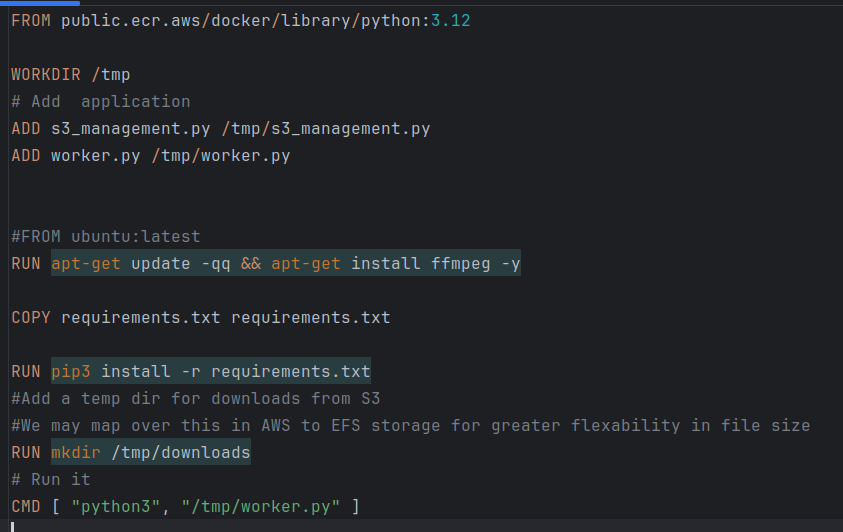
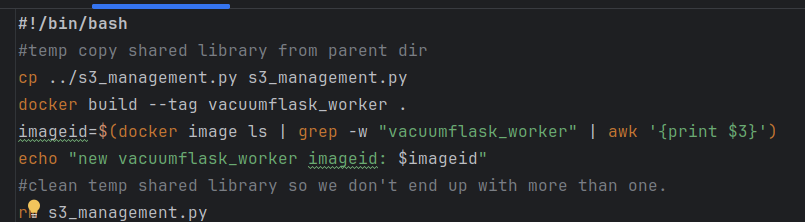
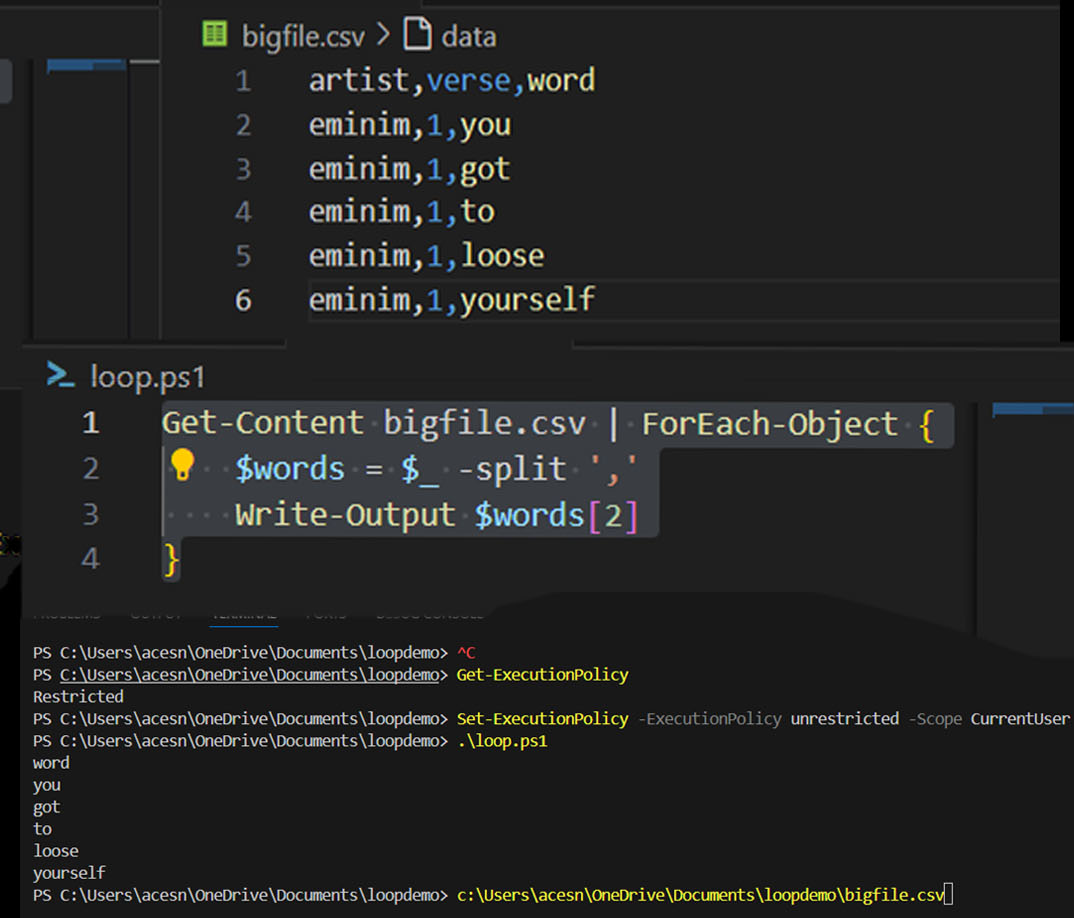
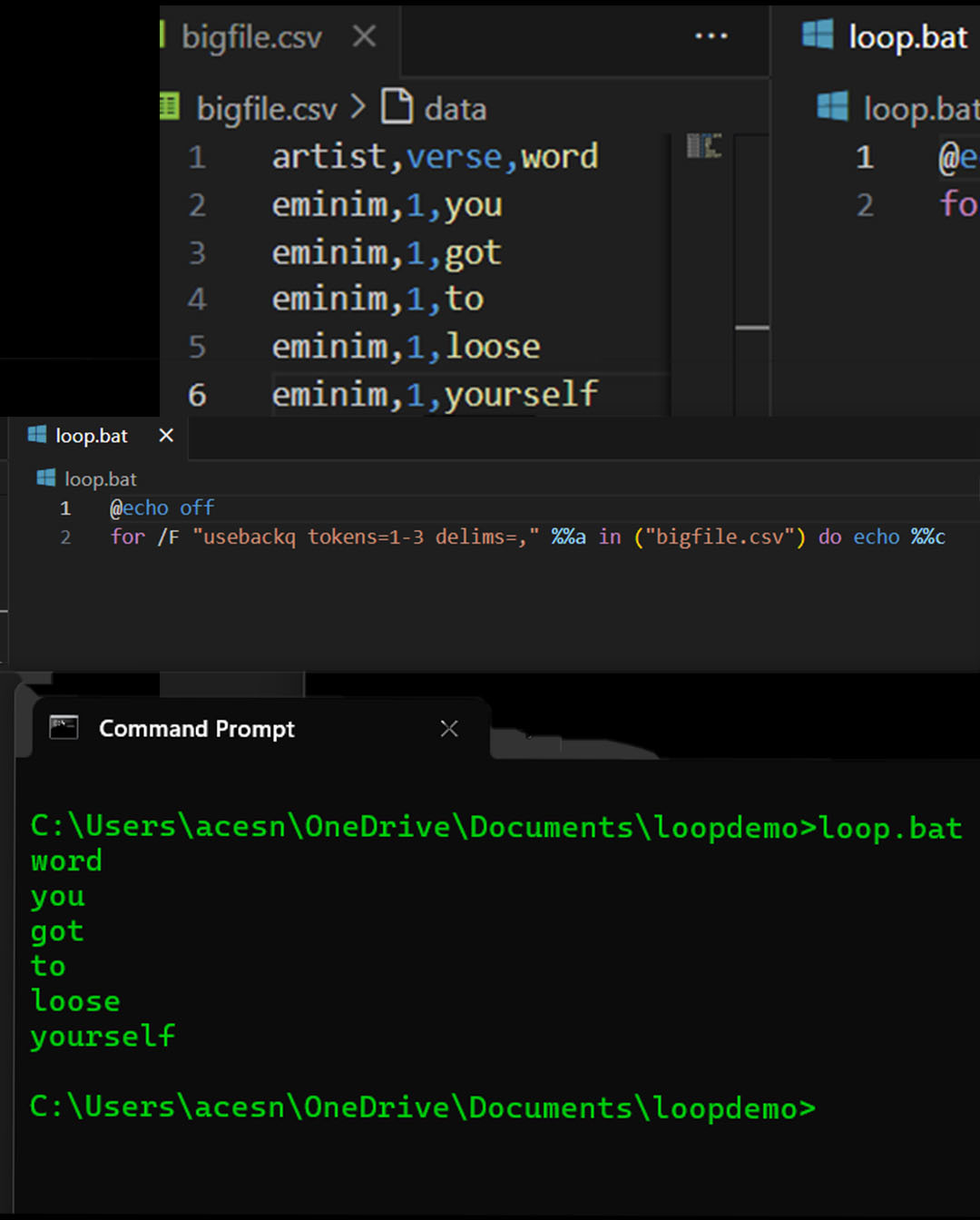
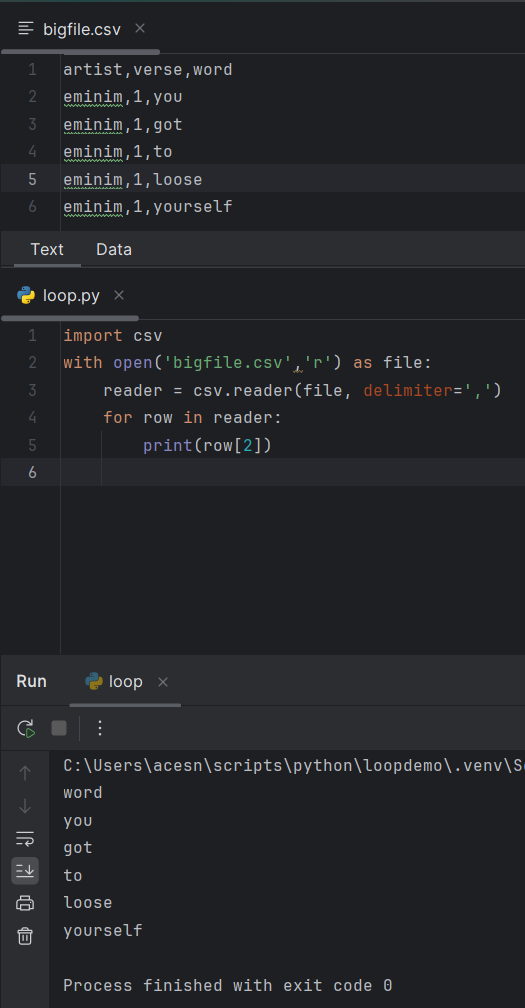
The data
| artist | verse | word |
| eminim | 1 | you |
| eminim | 1 | got |
| eminim | 1 | to |
| eminim | 1 | loose |
| eminim | 1 | yourself |
PowerShell
Get-Content bigfile.csv | ForEach-Object {
$words = $_ -split ','
Write-Output $words[2]
}
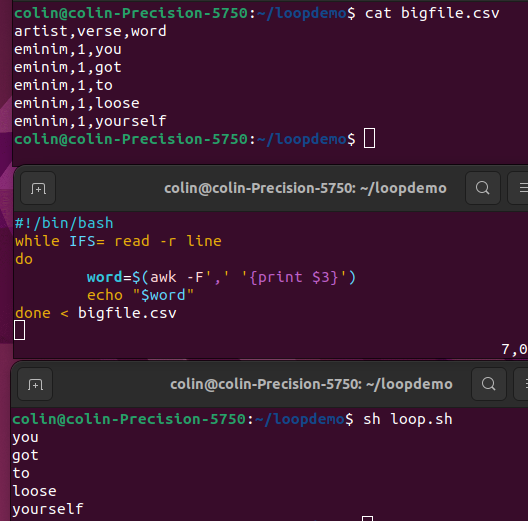
if [] if [[]] if [ $() ];At the end of the day one of my guys figured it out.
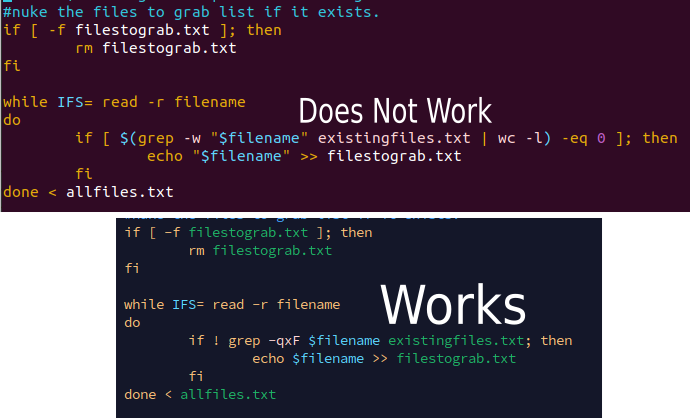
#!/bin/bash
secretobj=$(aws secretsmanager get-secret-value --secret-id "product/service/reporting" --region us-east-1)
rptpassword=$(echo $secretobj | jq ".SecretString" | sed 's/\\//g' | sed -E 's/^"//; s/"$//' | jq ".password" | sed -E 's/^"//; s/"$//' )
logfilename="service-report-log_$(date +'%Y-%m-%d').log"
echo "starting report run $(date '+%Y%m%d')" > "$logfilename"
ls service-reports | sort > existingfiles.txt
allfiles=$(sshpass -p "$rptpassword" sftp -oBatchMode=no -b - service-reports << !
cd ppreports/outgoing
ls
exit
!
)
#cleanup output from sftp server
echo "$allfiles" | sed -e '1,/^sftp> ls$/d' -e '/^sftp> cd ppreports\/outgoing$/d' -e '/^sftp> exit/d' | sort > allfiles.txt
echo "all files on server:\n $allfiles" >> "$logfilename"
#nuke the files to grab list if it exists.
if [ -f filestograb.txt ]; then
rm filestograb.txt
fi
while IFS= read -r filename
do
if ! grep -qxF $filename existingfiles.txt; then
echo $filename >> filestograb.txt
fi
done < allfiles.txt
comm -23 allfiles.txt existingfiles.txt > filestograb2.txt
if [ -f filestograb.txt ]; then
echo "files to grab:\n" >> "$logfilename"
cat filestograb.txt >> "$logfilename"
echo "starting scp copy\n"
while IFS= read -r filename
do
sshpass -p "$rptpassword" scp service-reports:ppreports/outgoing/$filename service-reports/$filename
done < filestograb.txt
else
echo "No files missing?"
fi
echo "ending report run $(date '+%Y%m%d')" >> "$logfilename"
#!/bin/bash
#Check if we have a parameter
if [ $# -eq 1 ]; then
#check if the parameter is a file that exists
if [ -f "$1" ]; then
unzip -o "$1"
rm "$1"
fi
fi
oldimage=$(docker images | grep -w vacuumflask | awk '{print $3}')
newimageid=$(sh build.sh | awk '{print $4}')
runninginstance=$(docker ps | grep -w "$oldimage" | awk '{print $1}')
docker kill "$runninginstance"
sh run.sh
nowrunninginstance=$(docker ps | grep -w "$newimageid" | awk '{print $1}')
docker ps
echo "new running instance id is: $nowrunninginstance"
Hashing files with openssl and comparing with beyond compare.
ls split *.{py,csv}> splitlist.txt
while IFS= read -r filename
do
splithash=$(openssl sha256 split/$filename | awk '{print $2}')
sourcehash=$(openssl sha256 $filename | awk '{print $2}')
#echo "Source hash $sourcehash and split hash $splithash"
if [[ "$splithash" != "$sourcehash" ]] && [ -f "$filename" ]; then
bcompare "split/$filename" "$filename"
else
echo "Skipping $filename as there was no change"
fi
Given the results of a aws s3 ls command, lets add up the size of the files.
awk '{sum+=$2;} END{print sum;}'
Add second column to a variable called sum and then print sum.
This weekend, I spent some time trying to look for patterns in what should be random file names. I started the process by writing some Python to read a text file with the results of an s3 ls command, break the file name into pieces for each character of the file name, and insert it into an SQLite3 database. I used some new-to-me bash techniques for code generation using a command line for loop. Along with an older sql creation by sql. This with the newer execute a command for each file line and I was in business.
#add column numbers
#for f = 1 to 50
#add 50 columns named f1 to f50
for f in {1..50}
do
sqlite3 fileanalysis.db "alter table files add column f$f text;"
done
#loop for f = 1 to 48:
#loop for dynamic sql insert statements in mass
for f in {1..48}
do
sqlite3 control.db "insert into file_name_position_charecter_counts (f,charecter) select distinct 'f$f', f$f from files order by f$f";
done
#loop through sql generating sql and run against our sqlite3 database.
while IFS= read -r sql
do
sqlite3 control.db "$sql" > sqllog.txt
done < control_counts.tsv
--Create update statements to do charecter counts
select 'update file_name_position_charecter_counts set count=(select count(*) from files where '
|| c.f || '=''' || c.charecter || ''') where id = ' || cast(c.id as text)
from file_name_position_charecter_counts c;
FROM public.ecr.aws/docker/library/python:3.12
WORKDIR /tmp
# Add sample application
ADD app.py /tmp/app.py
ADD objects.py /tmp/objects.py
ADD hash.py /tmp/hash.py
COPY templates /tmp/templates
COPY static /tmp/static
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
EXPOSE 8080
# Run it
CMD [ "waitress-serve", "app:app" ]
#!/bin/bash
docker build --tag vacuumflask .
imageid=$(docker image ls | grep -w "vacuumflask" | awk '{print $3}')
docker run --env-file "/home/colin/python/blog2/vacuumflask/.env" \
--volume /home/colin/python/blog2/vacuumflask/data:/tmp/data \
-p 8080:8080 \
"$imageid"
#!/bin/bash
destination="beanstalk/"
zipPrefix="vacuumflask-"
zipPostfix=$(date '+%Y%m%d')
zipFileName="$zipPrefix$zipPostfix.zip"
mkdir "$destination"
cp -a templates/. "$destination/templates"
cp -a static/. "$destination/static"
cp app.py "$destination"
cp Dockerfile "$destination"
cp hash.py "$destination"
cp objects.py "$destination"
cp requirements.txt "$destination"
cd "$destination"
zip -r "../$zipFileName" "."
cd ../
rm -r "$destination"
scp "$zipFileName" project:blog2
scp docker-build-run.sh project:blog2
ssh project
Next weekend I’ll need to figure out how to get it working with elastic-beanstalk and then work on feature parity.
This morning I automated my data sync between the old blog and the data storage system for the new one. This will allow me to keep up on how my newer posts will look on the pages I’m building as I slowly replace the existing functionality.
#!/bin/bash
# copy the files from my project box to a local data folder
scp -r project:/var/www/blog/blogdata/ /home/colin/python/blog2/vacuumflask/data/
# read the blog.yml file and export the ids, then remove extra --- values from stream
# and store the ids in a file called blog_ids.txt
yq eval '.id' data/blogdata/blog.yml | sed '/^---$/d' > data/blogdata/blog_ids.txt
# loop through the blog ids and query the sqlite3 database and check and see if they exist
# if they do not exist run the old_blog_loader pythong script to insert the missing record.
while IFS= read -r id
do
result=$(sqlite3 data/vacuumflask.db "select id from post where old_id='$id';")
if [ -z "$result" ]; then
python3 old_blog_loader.py data/blogdata/blog.yml data/vacuumflask.db "$id"
fi
done < data/blogdata/blog_ids.txt
# clean up blog ids file as it is no longer needed
rm data/blogdata/blog_ids.txt
echo "Done"
After getting chores done for the day I set about working on my new blog engine. This started out with getting flask templates working and after some back and forth that was sorted out. It then set in that I was repeating myself a lot because I skipped an ORM model. So I set about to write a blog class to handle loading, serialization, updates, and inserts. A round of testing later and a bunch of bugs were squashed.
A side quest today was to update all of the image paths from prior blog posts to use my CDN. I ended up using a combination of awk commands [ awk '{print $7}' images.txt > just_images.txt and awk -F '/' '{print $3}' image_names.txt > images2.txt] to get a good list of images to push to the CDN and then asked chatgpt to help me write a bash loop [ while IFS= read -r file; do aws s3 cp "$file" s3://cmh.sh; done < images2.txt ] to copy all the images.
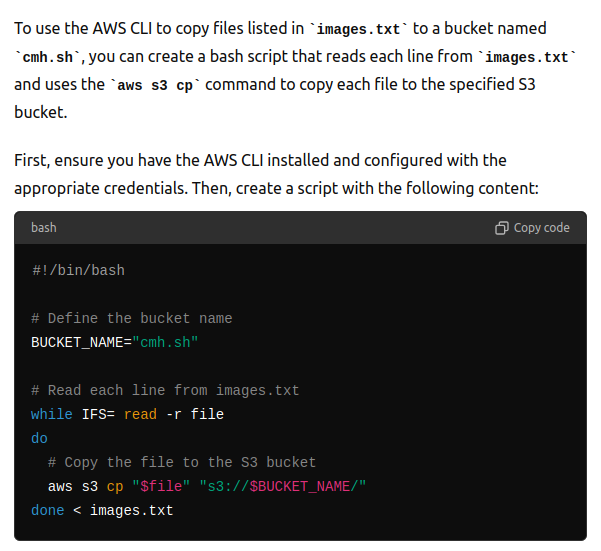 I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.
I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.