This weekend, I started off strong by going to the range with an old friend and then catching up over lunch. As far as the tech side of things, I broke down my serverless setup as it’s more expensive than a Wonderbox hosting containers. With that said I dusted off my nginx load balancer container, killed my ELB, and elastic ips, and retooled dns back to it’s humble roots. The following is Claude’s summary of the new features we implemented and the things we troubleshooted.
Dev work done this weekend
This weekend was a productive infrastructure and tooling sprint on the blog2/vacuumflask project. Here's a rundown of what got built and fixed.
Media Expiration System
Added a full lifecycle management system for media files. You can now set an expiration date on any file in the media library. After that date, a cleanup job removes it from S3 automatically. The expiration is stored in SQLite, visible in the media library UI with an edit button on each card, and also available at upload time. When a file is deleted manually, its expiration record is cleaned up too.
Headless API Authentication
Built a /api/login endpoint that issues a short-lived Bearer token using
VACUUMAPIKEYSALT + TOTP — no plaintext password required. This lets automated
scripts authenticate without storing credentials, using AWS Secrets Manager for the secret values
and pyotp for one-time passwords.
Lambda Cleanup Cron
Created cron/cleanup_expired.py — a Lambda-compatible handler that logs in via the
headless API and calls /admin/cleanup_expired. It logs structured output to
CloudWatch under the cron log group via watchtower, with each run
getting its own stream. Also ships as a local cron.sh that can be called from the
system crontab, scheduled for 12:01 AM daily.
MCP Server
Made the blog discoverable to AI assistants via the
Model Context Protocol. A FastMCP server exposes
blog posts, tags, and search as resources and tools. It runs as a Docker container with SSE
transport proxied through nginx at /mcp/, and is advertised to clients via
/.well-known/mcp.json and a tag in the page
header.
Blog Styling Modernization
Rewrote style.css with CSS variables, a sticky header, card-style post layout,
and a modernized tag cloud panel. Fixed a specificity bug where tags were rendering white-on-white,
and another where tag size weighting was overridden by the admin nav styles — so the tag cloud
now correctly reflects content volume.
Nginx + Certbot Infrastructure
Rebuilt the load balancer container to manage its own TLS certificates. On startup it generates self-signed certs so nginx can start, then immediately replaces them with Let's Encrypt certificates via the HTTP-01 webroot challenge. A cron job inside the container handles daily renewal at 3 AM and 3 PM. Certificates persist across restarts via Docker named volumes.
Redis Connection Fix
Tracked down a TimeoutError in the Redis client caused by a stale EC2 internal IP
in the server's .env file. The Flask container runs with --network=host
but Valkey runs in bridge mode, so Docker's loopback forwarding doesn't apply. The fix was to
use Valkey's Docker bridge IP (172.17.0.2) directly.
The actual code to implement WatchTower in my code:
# Configure the Flask logger
logger = logging.getLogger(__name__)
cloud_watch_stream_name = "vacuum_flask_log_{0}_{1}".format(platform.node(),timeobj.strftime("%Y%m%d%H%M%S"))
cloudwatch_handler = CloudWatchLogHandler(
log_group_name='vacuum_flask', # Replace with your desired log group name
stream_name=cloud_watch_stream_name, # Replace with a stream name
)
app.logger.addHandler(cloudwatch_handler)
app.logger.setLevel(logging.INFO)
IAM permissions required
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": "*"
}
]
}
Finishing touches
The last thing that proved to be an issue was that boto3 couldn’t find the default region in my containers. This has come up before but today was I was able to find a way around it by adding a default aws cli config file to my deployment and telling boto3 where to find it by using the environment variable AWS_CONFIG_FILE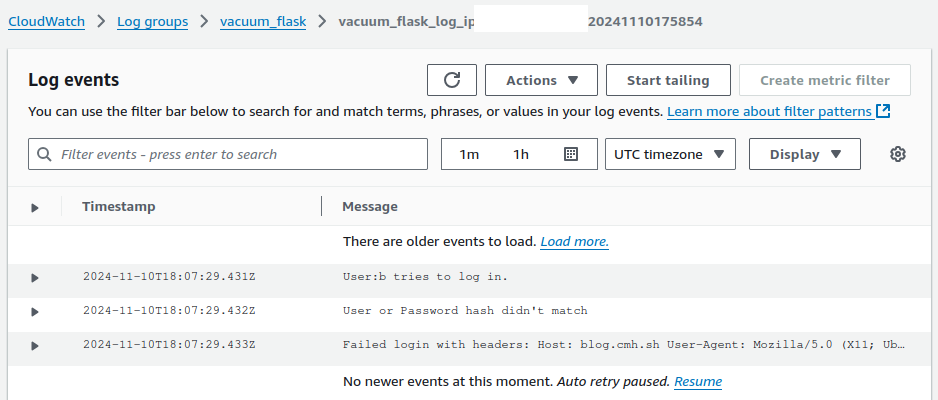
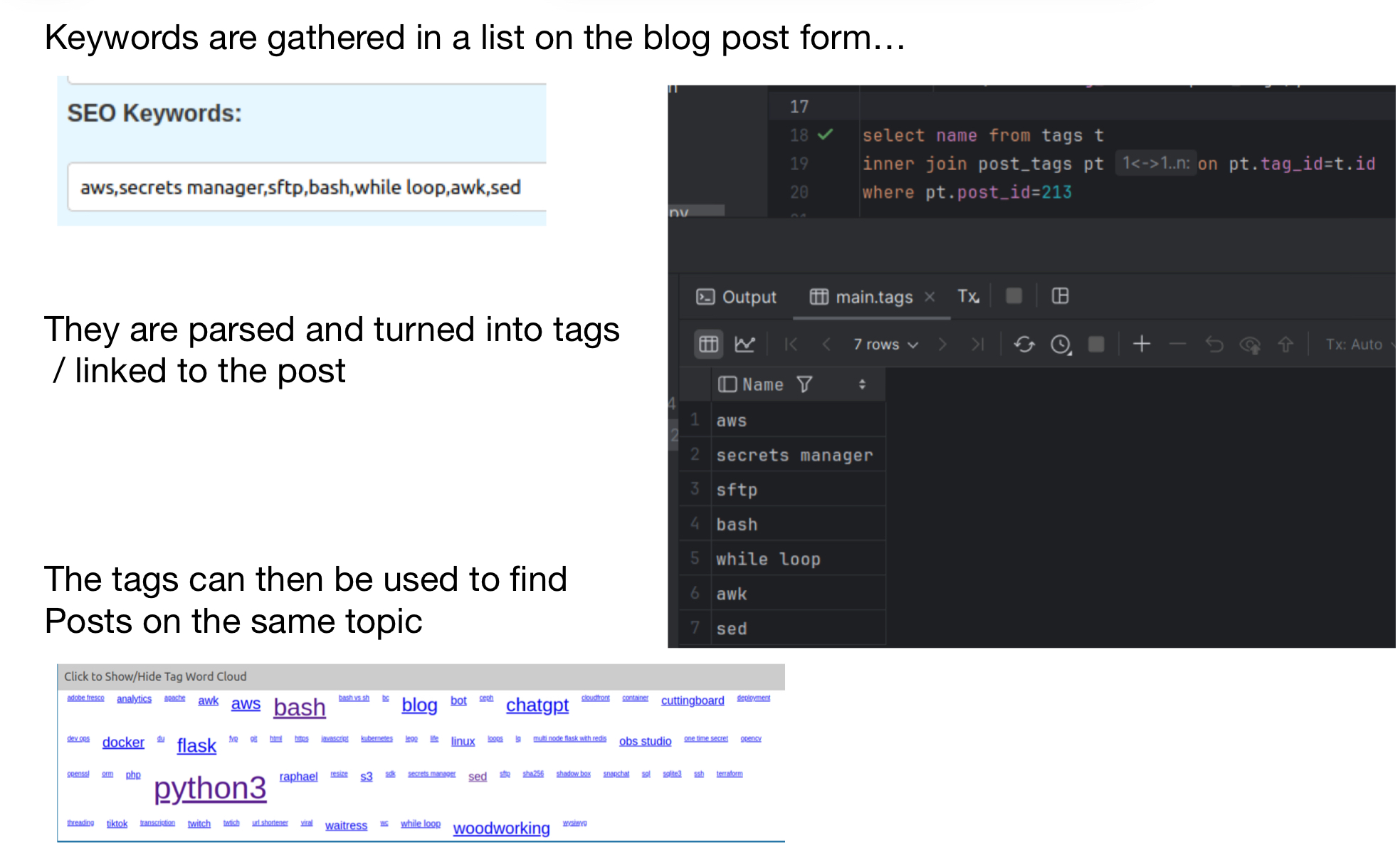
- Redis for shared server session state
- Added health checks to the apache load balancer
- Added EFS, docker, and the required networking to the mail server.
- Fixed issue with deployment pipeline not refreshing image
- Limited main page to 8 posts and added links at the bottom to everything else so it will still get indexed.
def listen_local(self):
loop = asyncio.get_event_loop()
print("Firing off Flask")
thread1 = threading.Thread(target=lambda: self.myWebServ.run(
host=self.config_data["flask_host_ip"], port=self.config_data["flask_host_port"],
use_reloader=False, debug=True), args=()).start()
#self.myWebServ.run()
self.myWebServ_up = True
print("Listening to local Mic")
thread2 = threading.Thread(loop.run_until_complete(self.basic_transcribe()))
#loop.run_until_complete(self.basic_transcribe())
#loop.run_until_complete(self.launch_flask_server())
loop.close()
Welp, the “new” blog is live. It’s running on python 3.12 with the latest build of flask and waitress. This version of my blog is containerized and actually uses a database. A very basic concept I know. I considered running the blog on the elastic container service and also as an elastic beanstalk app. The problem with both of those is that I don’t really need the extra capacity and I already have reserved instances purchased for use with my existing ec2 instances. I’m not sure how well flask works with multiple nodes, I may have to play around with that for resiliency sake. For now we are using apache2 as a reverse https proxy with everything hosted on my project box.
Todo items: SEO for posts, RSS for syndication and site map, fixing s3 access running from a docker container. Everything else should be working. There is also a sorting issue of the blog posts that I need to work out.
FROM public.ecr.aws/docker/library/python:3.12
WORKDIR /tmp
# Add sample application
ADD app.py /tmp/app.py
ADD objects.py /tmp/objects.py
ADD hash.py /tmp/hash.py
COPY templates /tmp/templates
COPY static /tmp/static
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
EXPOSE 8080
# Run it
CMD [ "waitress-serve", "app:app" ]
#!/bin/bash
docker build --tag vacuumflask .
imageid=$(docker image ls | grep -w "vacuumflask" | awk '{print $3}')
docker run --env-file "/home/colin/python/blog2/vacuumflask/.env" \
--volume /home/colin/python/blog2/vacuumflask/data:/tmp/data \
-p 8080:8080 \
"$imageid"
#!/bin/bash
destination="beanstalk/"
zipPrefix="vacuumflask-"
zipPostfix=$(date '+%Y%m%d')
zipFileName="$zipPrefix$zipPostfix.zip"
mkdir "$destination"
cp -a templates/. "$destination/templates"
cp -a static/. "$destination/static"
cp app.py "$destination"
cp Dockerfile "$destination"
cp hash.py "$destination"
cp objects.py "$destination"
cp requirements.txt "$destination"
cd "$destination"
zip -r "../$zipFileName" "."
cd ../
rm -r "$destination"
scp "$zipFileName" project:blog2
scp docker-build-run.sh project:blog2
ssh project
Next weekend I’ll need to figure out how to get it working with elastic-beanstalk and then work on feature parity.
This morning I automated my data sync between the old blog and the data storage system for the new one. This will allow me to keep up on how my newer posts will look on the pages I’m building as I slowly replace the existing functionality.
#!/bin/bash
# copy the files from my project box to a local data folder
scp -r project:/var/www/blog/blogdata/ /home/colin/python/blog2/vacuumflask/data/
# read the blog.yml file and export the ids, then remove extra --- values from stream
# and store the ids in a file called blog_ids.txt
yq eval '.id' data/blogdata/blog.yml | sed '/^---$/d' > data/blogdata/blog_ids.txt
# loop through the blog ids and query the sqlite3 database and check and see if they exist
# if they do not exist run the old_blog_loader pythong script to insert the missing record.
while IFS= read -r id
do
result=$(sqlite3 data/vacuumflask.db "select id from post where old_id='$id';")
if [ -z "$result" ]; then
python3 old_blog_loader.py data/blogdata/blog.yml data/vacuumflask.db "$id"
fi
done < data/blogdata/blog_ids.txt
# clean up blog ids file as it is no longer needed
rm data/blogdata/blog_ids.txt
echo "Done"
After getting chores done for the day I set about working on my new blog engine. This started out with getting flask templates working and after some back and forth that was sorted out. It then set in that I was repeating myself a lot because I skipped an ORM model. So I set about to write a blog class to handle loading, serialization, updates, and inserts. A round of testing later and a bunch of bugs were squashed.
A side quest today was to update all of the image paths from prior blog posts to use my CDN. I ended up using a combination of awk commands [ awk '{print $7}' images.txt > just_images.txt and awk -F '/' '{print $3}' image_names.txt > images2.txt] to get a good list of images to push to the CDN and then asked chatgpt to help me write a bash loop [ while IFS= read -r file; do aws s3 cp "$file" s3://cmh.sh; done < images2.txt ] to copy all the images.
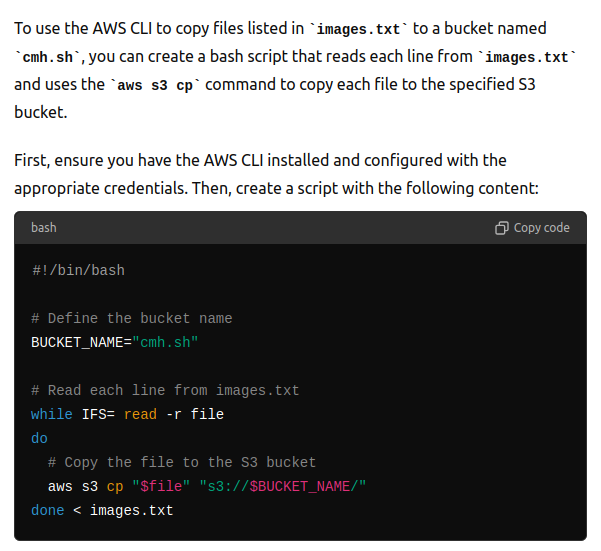 I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.
I’ve seen one of my more Linux savvy coworkers write these loops on the fly and it is always impressive. I streamed the first couple hours of development and encountered a number of bugs with Raphael bot that I’ll see about fixing tomorrow.